https://blog.philip-huang.tech/?page=vlmo
論文連結
統一視覺語言預訓練模型 (VLMo) 採用了共同學習雙編碼器與融合編碼器的方式,並運用階段性預訓練策略。實驗結果顯示,VLMo 在各種視覺-文字任務上達到了最先進的表現。
MoME Transformer
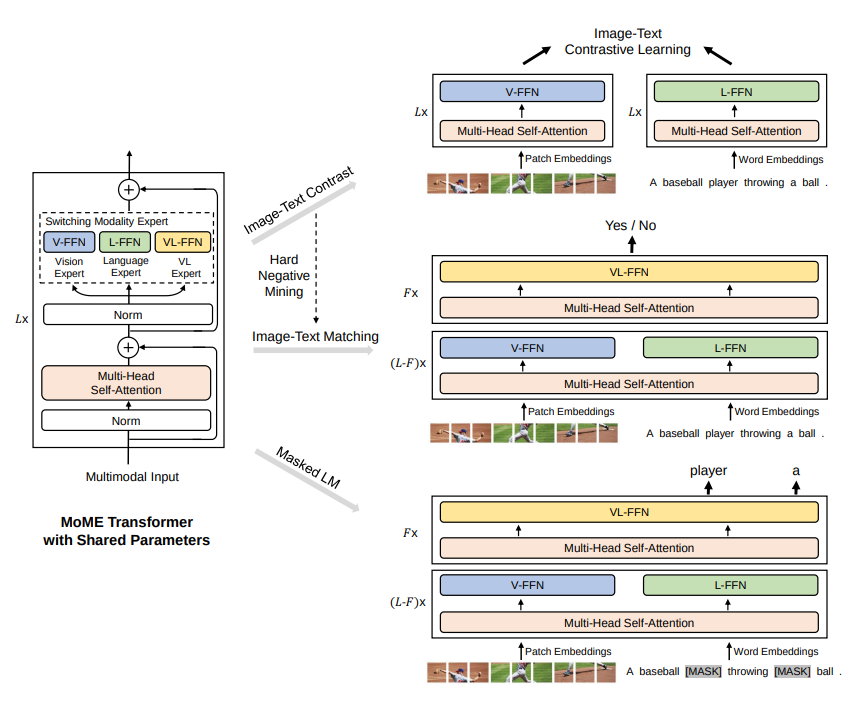
VLMo 使用了 MoME Transformer, 它可以編碼:影像、文字以及影像-文字對。
使用一組模態專家池來取代標準 Transformer 中的前饋神經網絡 (FFN)。
透過切換專家來捕捉模態特定的信息。
三種專家:
三種形式的輸入(影像、文字和有巷-文字),分別由兩種編碼器:文字編碼器與影像編碼器,處理編碼過程;後續根據輸入類型的不同,送到MoME-FFN層的時候由三個不同的專家處理。
| 輸入類型 | 編碼器
https://blog.philip-huang.tech/?page=vlmo
論文連結
統一視覺語言預訓練模型 (VLMo) 採用了共同學習雙編碼器與融合編碼器的方式,並運用階段性預訓練策略。實驗結果顯示,VLMo 在各種視覺-文字任務上達到了最先進的表現。
MoME Transformer
VLMo 使用了 MoME Transformer, 它可以編碼:影像、文字以及影像-文字對。
使用一組模態專家池來取代標準 Transformer 中的前饋神經網絡 (FFN)。
透過切換專家來捕捉模態特定的信息。
三種專家:
三種形式的輸入(影像、文字和有巷-文字),分別由兩種編碼器:文字編碼器與影像編碼器,處理編碼過程;後續根據輸入類型的不同,送到MoME-FFN層的時候由三個不同的專家處理。
| 輸入類型 | 編碼器