https://blog.philip-huang.tech/?page=dpo
論文連結: https://arxiv.org/abs/2305.18290
RLHF 是複雜且不穩定的,首先訓練一個獎勵模型以反應人類偏好,然後利用強化學習微調語言模型來最大化估計獎勵,在過程中約束微調的模型不可以偏離原始模型太多。
標準的RLHF背後使用PPO技術。
我們介紹一個可用於RLHF的參數化隱式獎勵模型,讓我們可以僅用自監督方法解決標準RLHF問題。
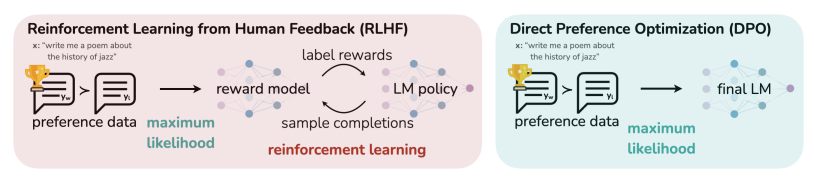
DPO優化人類偏好,同時避免使用強化學習。現有的 RLHF 方法首先將獎勵模型擬合到一個包含提示和人類對不同回應對的偏好的數據集中,然後使用強化學習找到最大化學習獎勵的策略。相比之下,DPO直接優化最能滿足偏好的策略,使用簡單的分類目標,擬合一個隱式獎勵模型,其相應的最優策略可以以封閉形式提取。
我們將展示現有 RL 方法的訓練目標可以
https://blog.philip-huang.tech/?page=dpo
論文連結: https://arxiv.org/abs/2305.18290
RLHF 是複雜且不穩定的,首先訓練一個獎勵模型以反應人類偏好,然後利用強化學習微調語言模型來最大化估計獎勵,在過程中約束微調的模型不可以偏離原始模型太多。
我們介紹一個可用於RLHF的參數化隱式獎勵模型,讓我們可以僅用自監督方法解決標準RLHF問題。
我們將展示現有 RL 方法的訓練目標可以