diff --git a/doc/api-reference.md b/doc/api-reference.md
index 0535e210..6ff8293f 100644
--- a/doc/api-reference.md
+++ b/doc/api-reference.md
@@ -6,11 +6,15 @@ This page documents the API of Ohm/JS, a JavaScript library for working with gra
**NOTE:** For grammars defined in a JavaScript string literal (i.e., not in a separate .ohm file), it's recommended to use a [template literal with the String.raw tag](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/raw).
-ohm.grammar(source: string, optNamespace?: object) → Grammar
+```ts
+ohm.grammar(source: string, optNamespace?: object): Grammar
+```
Instantiate the Grammar defined by `source`. If specified, `optNamespace` is an object in which references to other grammars should be resolved. For example, if the grammar source begins with an inheritance declaration like `MyGrammar <: OtherGrammar { ... }`, then `optNamespace` should have a property named `OtherGrammar`.
-ohm.grammars(source: string, optNamespace?: object) → object
+```ts
+ohm.grammars(source: string, optNamespace?: object): object
+```
Create a new object containing Grammar instances for all of the grammars defined in `source`. As with `ohm.grammar`, if `optNamespace` is specified, it is an object in which references to other grammars should be resolved. Additionally, it will be the prototype of the returned object.
@@ -21,7 +25,7 @@ Here is an example of instantiating a Grammar:
const ohm = require('ohm-js');
-->
-```
+```js
const parentDef = String.raw`
Parent {
start = "parent"
@@ -36,7 +40,8 @@ const parentGrammar = ohm.grammar(parentDef);
-->
In the next example We instantiate a new grammar, *Child*, that inherits from our *Parent* grammar. We use the `ohm.grammars` method, which returns an object of our grammars:
-```
+
+```js
const childDef = String.raw`
Child <: Parent {
start := "child"
@@ -54,7 +59,8 @@ console.log(Object.keys(childGrammar));
-->
You could also concatenate the grammar definitions, and then instantiate them. This results in an object with both Grammars:
-```
+
+```js
const combinedDef = parentDef.concat(childDef);
const grammars = ohm.grammars(combinedDef);
console.log(Object.keys(grammars));
@@ -70,25 +76,38 @@ console.log(Object.keys(grammars));
A Grammar instance `g` has the following methods:
-g.match(str: string, optStartRule?: string) → MatchResult
+
+```ts
+g.match(str: string, optStartRule?: string): MatchResult
+```
Try to match `str` against `g`, returning a [MatchResult](#matchresult-objects). If `optStartRule` is given, it specifies the rule on which to start matching. By default, the start rule is inherited from the supergrammar, or if there is no supergrammar specified, it is the first rule in `g`'s definition.
-g.matcher()
+```ts
+g.matcher()
+```
Create a new [Matcher](#matcher-objects) object which supports incrementally matching `g` against a changing input string.
-g.trace(str: string, optStartRule?: string) → Trace
+
+```ts
+g.trace(str: string, optStartRule?: string): Trace
+```
Try to match `str` against `g`, returning a Trace object. `optStartRule` has the same meaning as in `g.match`. Trace objects have a `toString()` method, which returns a string which summarizes each parsing step (useful for debugging).
-g.createSemantics() → Semantics
+```ts
+g.createSemantics(): Semantics
+```
-Create a new [Semantics](#semantics) object for `g`.
+Create a new [Semantics](#semantics-objects) object for `g`.
-g.extendSemantics(superSemantics: Semantics) → Semantics
+
+```ts
+g.extendSemantics(superSemantics: Semantics): Semantics
+```
-Create a new [Semantics](#semantics) object for `g` that inherits all of the operations and attributes in `superSemantics`. `g` must be a descendent of the grammar associated with `superSemantics`.
+Create a new [Semantics](#semantics-objects) object for `g` that inherits all of the operations and attributes in `superSemantics`. `g` must be a descendent of the grammar associated with `superSemantics`.
## Matcher objects
@@ -96,23 +115,33 @@ Matcher objects can be used to incrementally match a changing input against the
A Matcher instance `m` has the following methods:
-m.getInput() → string
+```ts
+m.getInput(): string
+```
Return the current input string.
-m.setInput(str: string)
+```ts
+m.setInput(str: string)
+```
Set the input string to `str`.
-m.replaceInputRange(startIdx: number, endIdx: number, str: string)
+```ts
+m.replaceInputRange(startIdx: number, endIdx: number, str: string)
+```
Edit the current input string, replacing the characters between `startIdx` and `endIdx` with `str`.
-m.match(optStartRule?: string) → MatchResult
+```ts
+m.match(optStartRule?: string): MatchResult
+```
Like [Grammar's `match` method](#Grammar.match), but operates incrementally.
-m.trace(optStartRule?: string) → Trace
+```ts
+m.trace(optStartRule?: string): Trace
+```
Like [Grammar's `trace` method](#Grammar.trace), but operates incrementally.
@@ -122,11 +151,15 @@ Internally, a successful MatchResult contains a _parse tree_, which is made up o
A MatchResult instance `r` has the following methods:
-r.succeeded() → boolean
+```ts
+r.succeeded(): boolean
+```
Return `true` if the match succeeded, otherwise `false`.
-r.failed() → boolean
+```ts
+r.failed(): boolean
+```
Return `true` if the match failed, otherwise `false`.
@@ -134,23 +167,31 @@ Return `true` if the match failed, otherwise `false`.
When `r.failed()` is `true`, `r` has the following additional properties and methods:
-r.message: string
+```ts
+r.message: string
+```
Contains a message indicating where and why the match failed. This message is suitable for end users of a language (i.e., people who do not have access to the grammar source).
-r.shortMessage: string
+```ts
+r.shortMessage: string
+```
Contains an abbreviated version of `r.message` that does not include an excerpt from the invalid input.
-r.getRightmostFailurePosition() → number
+```ts
+r.getRightmostFailurePosition(): number
+```
Return the index in the input stream at which the match failed.
-r.getRightmostFailures() → Array
+```ts
+r.getRightmostFailures(): Array
+```
Return an array of Failure objects describing the failures the occurred at the rightmost failure position.
-Semantics, Operations, and Attributes
+## Semantics, Operations, and Attributes
An Operation represents a function that can be applied to a successful match result. Like a [Visitor](http://en.wikipedia.org/wiki/Visitor_pattern), an operation is evaluated by recursively walking the parse tree, and at each node, invoking the matching semantic action from its _action dictionary_.
@@ -165,21 +206,29 @@ This returns a parse node, whose properties correspond to the operations and att
A Semantics instance `s` has the following methods, which all return `this` so they can be chained:
-mySemantics.addOperation(nameOrSignature: string, actionDict: object) → Semantics
+```ts
+mySemantics.addOperation(nameOrSignature: string, actionDict: object): Semantics
+```
Add a new Operation to this Semantics, using the [semantic actions](#semantic-actions) contained in `actionDict`. The first argument is either a name (e.g. `'prettyPrint'`) or a _signature_ which specifies the operation name and zero or more named parameters (e.g., `'prettyPrint()'`, `'prettyPrint(depth, strict)'`). It is an error if there is already an operation or attribute called `name` in this semantics.
If the operation has arguments, they are accessible via `this.args` within a semantic action. For example, `this.args.depth` would hold the value of the `depth` argument for the current action.
-mySemantics.addAttribute(name: string, actionDict: object) → Semantics
+```ts
+mySemantics.addAttribute(name: string, actionDict: object): Semantics
+```
Exactly like `semantics.addOperation`, except it will add an Attribute to the semantics rather than an Operation.
-mySemantics.extendOperation(name: string, actionDict: object) → Semantics
+```ts
+mySemantics.extendOperation(name: string, actionDict: object): Semantics
+```
Extend the Operation named `name` with the semantic actions contained in `actionDict`. `name` must be the name of an operation in the super semantics — i.e., you must first extend the Semantics via [`extendSemantics`](#extendSemantics) before you can extend any of its operations.
-semantics.extendAttribute(name: string, actionDict: object) → Semantics
+```ts
+semantics.extendAttribute(name: string, actionDict: object): Semantics
+```
Exactly like `semantics.extendOperation`, except it will extend an Attribute of the super semantics rather than an Operation.
@@ -189,7 +238,7 @@ A semantic action is a function that computes the value of an operation or attri
- _Rule application_, or _non-terminal_ nodes, which correspond to rule application expressions
- _Terminal_ nodes, for string and number literals, and keyword expressions
-- _Iteration_ nodes, which are associated with expressions inside a [repetition operator](./syntax-reference.md#repetition-operators) (`*`, `+`, and `?`)
+- _Iteration_ nodes, which are associated with expressions inside a [repetition operator](./syntax-reference.md#repetition-operators---) (`*`, `+`, and `?`)
Generally, you write a semantic action for each rule in your grammar, and store them together in an _action dictionary_. For example, given the following grammar:
@@ -239,7 +288,7 @@ The matching semantic action for a particular node is chosen as follows:
- On a terminal node (e.g., a node produced by the parsing expression `"hello"`), use the semantic action named `_terminal`.
- On an iteration node (e.g., a node produced by the parsing expression `letter+`), use the semantic action named `_iter`.
-The `_iter`, `_nonterminal`, and `_terminal` actions are sometimes called _special actions_. `_iter` and `_nonterminal` take a variable number of arguments, which are typically captured into an array using [rest parameter syntax](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/rest_parameters) , e.g. `_iter(...children) { ... }`. The `_terminal` action takes no arguments.
+The `_iter`, `_nonterminal`, and `_terminal` actions are sometimes called _special actions_. `_iter` and `_nonterminal` take a variable number of arguments, which are typically captured into an array using [rest parameter syntax](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/rest_parameters) , e.g. _iter(...children) { ... }. The `_terminal` action takes no arguments.
-```
+```js
s.addOperation('upper()', {
Start(list) {
return list.asIteration().children.map(c => c.upper());
diff --git a/doc/contributor-guide.md b/doc/contributor-guide.md
index 99405929..244d3c05 100644
--- a/doc/contributor-guide.md
+++ b/doc/contributor-guide.md
@@ -18,12 +18,16 @@ You also need to install [pnpm](https://pnpm.io/).
First, clone the repository:
- git clone https://github.com/cdglabs/ohm.git
+```bash
+git clone https://github.com/cdglabs/ohm.git
+```
Then, install the dev dependencies:
- cd ohm
- pnpm install
+```bash
+cd ohm
+pnpm install
+```
_Note: the `postinstall` script (which is automatically run by `pnpm install`)
will install a git pre-commit hook. See [here](#pre-commit-checks) for more
@@ -60,7 +64,7 @@ sense to disable the error:
- If you added new `console.log` statement, and **you are sure that it is
actual useful**, you can disable the warning like this:
- ```
+ ```js
console.log('a useful message'); // eslint-disable-line no-console
```
diff --git a/doc/design/miniohm.md b/doc/design/miniohm.md
index d0785ddb..07fa2b75 100644
--- a/doc/design/miniohm.md
+++ b/doc/design/miniohm.md
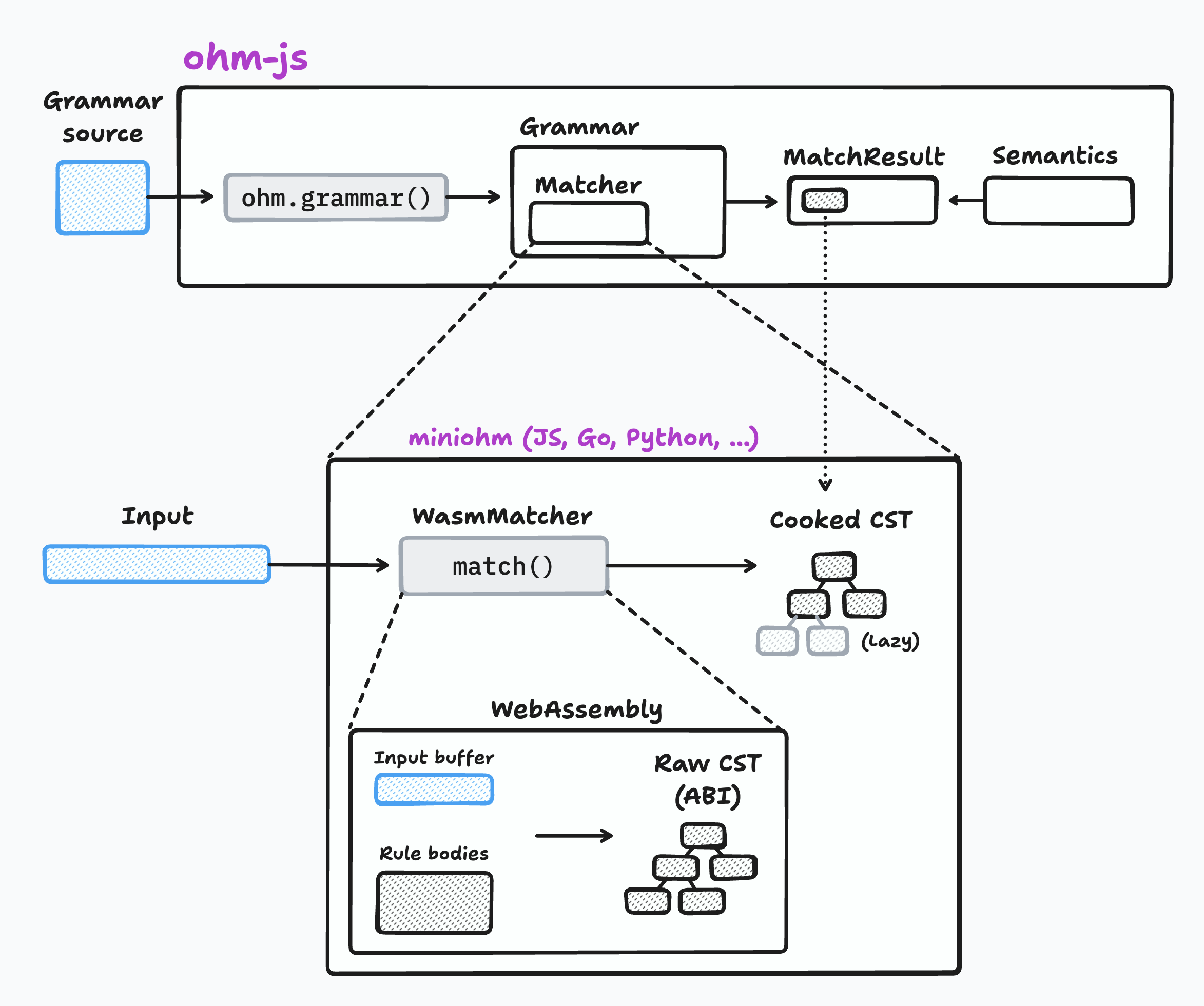
@@ -6,4 +6,4 @@ Eventually, we want the WebAssembly-based matcher to be the core of `ohm-js`. Id
Here's how I'm picturing this:
-
+
diff --git a/doc/errors.md b/doc/errors.md
index be3b0601..6af0e7c4 100644
--- a/doc/errors.md
+++ b/doc/errors.md
@@ -9,13 +9,15 @@ from a grammar definition.
Example:
- Uncaught ohm.error.GrammarSyntaxError: Failed to parse grammar:
- Line 5, col 11:
- 4 | G {
- > 5 | start = *x
- ^
- 6 | }
- Expected "~", "&", "#", an identifier, "\"", a number, "(", "[", "``", "{", "--", "|", or "}"
+```
+Uncaught ohm.error.GrammarSyntaxError: Failed to parse grammar:
+Line 5, col 11:
+ 4 | G {
+> 5 | start = *x
+ ^
+ 6 | }
+Expected "~", "&", "#", an identifier, "\"", a number, "(", "[", "``", "{", "--", "|", or "}"
+```
Indicates that the grammar definition is not well-formed according to the syntax
of the Ohm language. See the [syntax reference](./syntax-reference.md) for more
@@ -25,7 +27,9 @@ details.
Example:
- Uncaught ohm.error.UndeclaredGrammar: Grammar Foo is not declared in namespace [object Object]
+```
+Uncaught ohm.error.UndeclaredGrammar: Grammar Foo is not declared in namespace [object Object]
+```
Indicates that the grammar definition refers to another grammar by name, but
that name does not refer to a grammar that Ohm knows about. This can happen
@@ -49,7 +53,9 @@ fixes:
Example:
- Uncaught ohm.error.DuplicateGrammarDeclaration: Grammar G is already declared in namespace [object Object]
+```
+Uncaught ohm.error.DuplicateGrammarDeclaration: Grammar G is already declared in namespace [object Object]
+```
Occurs when a grammar definition defines a grammar with the same name
as an existing grammar in the same namespace. Possible fixes:
@@ -62,7 +68,9 @@ as an existing grammar in the same namespace. Possible fixes:
Example:
- Uncaught ohm.error.UndeclaredRule: Rule lettr is not declared in grammar G
+```
+Uncaught ohm.error.UndeclaredRule: Rule lettr is not declared in grammar G
+```
Occurs when the body of a rule refers to a another rule that is not defined in
the grammar or in any of its supergrammars.
@@ -71,7 +79,9 @@ the grammar or in any of its supergrammars.
Example:
- Uncaught ohm.error.CannotOverrideUndeclaredRule: Cannot override rule foo because it is not declared in BuiltInRules
+```
+Uncaught ohm.error.CannotOverrideUndeclaredRule: Cannot override rule foo because it is not declared in BuiltInRules
+```
Occurs when a rule is being _overridden_ (using `:=`), but no rule with that name
exists in the supergrammar. Learn more about defining, extending, and overriding
@@ -81,7 +91,9 @@ rules in the [syntax reference](syntax-reference.md#defining-extending-and-overr
Example:
- Uncaught ohm.error.CannotExtendUndeclaredRule: Cannot extend rule start foo it is not declared in BuiltInRules
+```
+Uncaught ohm.error.CannotExtendUndeclaredRule: Cannot extend rule start foo it is not declared in BuiltInRules
+```
Occurs when a rule is being _extended_ (using `+=`), but no rule with that name
exists in the supergrammar. Learn more about defining, extending, and overriding
@@ -91,7 +103,9 @@ rules in the [syntax reference](syntax-reference.md#defining-extending-and-overr
Example:
- Uncaught ohm.error.DuplicateRuleDeclaration: Duplicate declaration for rule 'letter' in grammar 'G' (originally declared in grammar 'BuiltInRules')
+```
+Uncaught ohm.error.DuplicateRuleDeclaration: Duplicate declaration for rule 'letter' in grammar 'G' (originally declared in grammar 'BuiltInRules')
+```
Occurs when a rule is being _defined_ (using `=`), but a rule with that name
already exists in the grammar or supergrammar. If it exists in the supergrammar,
diff --git a/doc/extras.md b/doc/extras.md
index f68ecce4..f739d462 100644
--- a/doc/extras.md
+++ b/doc/extras.md
@@ -17,8 +17,8 @@ To do so, a generic operation is used that can be configure by the optional mapp
The resulting AST is inspired by the [ECMAScript Tree](https://github.com/estree/estree) format that is the output of popular JavaScript parsers like [acorn](https://github.com/ternjs/acorn) or [esprima](http://esprima.org/).
-
-**Example:**
+
+### Example
+
+```
+
+or
+
+```html
+
+
+```
+
+This creates a global variable named `ohm`.
+
+### Node.js
+
+First, install the `ohm-js` package with your package manager:
+
+- [npm](http://npmjs.org): `npm install ohm-js`
+- [Yarn](https://yarnpkg.com/): `yarn add ohm-js`
+- [pnpm](https://pnpm.io/): `pnpm add ohm-js`
+
+Then, you can use `require` to use Ohm in a script:
+
+
+
+```js
+const ohm = require('ohm-js');
+```
+
+Ohm can also be imported as an ES module:
+
+```js
+import * as ohm from 'ohm-js';
+```
+
+### Deno
+
+To use Ohm from [Deno](https://deno.land/):
+
+```js
+import * as ohm from 'https://unpkg.com/ohm-js@17';
+```
+
+## Basics
+
+### Defining Grammars
+
+
+
+To use Ohm, you need a grammar that is written in the Ohm language. The grammar provides a formal
+definition of the language or data format that you want to parse. There are a few different ways
+you can define an Ohm grammar:
+
+- The simplest option is to define the grammar directly in a JavaScript string and instantiate it
+ using `ohm.grammar()`. In most cases, you should use a [template literal with String.raw](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/raw):
+
+ ```js
+ const myGrammar = ohm.grammar(String.raw`
+ MyGrammar {
+ greeting = "Hello" | "Hola"
+ }
+ `);
+ ```
+
+- **In Node.js**, you can define the grammar in a separate file, and read the file's contents and instantiate it using `ohm.grammar(contents)`:
+
+ In `myGrammar.ohm`:
+
+ ```
+ MyGrammar {
+ greeting = "Hello" | "Hola"
+ }
+ ```
+
+ In JavaScript:
+
+ ```js
+ const fs = require('fs');
+ const ohm = require('ohm-js');
+ const contents = fs.readFileSync('myGrammar.ohm', 'utf-8');
+ const myGrammar = ohm.grammar(contents);
+ ```
+
+For more information, see [Instantiating Grammars](api-reference.md#instantiating-grammars) in the API reference.
+
+### Using Grammars
+
+
+
+
+
+Once you've instantiated a grammar object, use the grammar's `match()` method to recognize input:
+
+```js
+const userInput = 'Hello';
+const m = myGrammar.match(userInput);
+if (m.succeeded()) {
+ console.log('Greetings, human.');
+} else {
+ console.log("That's not a greeting!");
+}
+```
+
+The result is a MatchResult object. You can use the `succeeded()` and `failed()` methods to see whether the input was recognized or not.
+
+For more information, see the [API Reference](api-reference.md).
+
+## Debugging
+
+Ohm has two tools to help you debug grammars: a text trace, and a graphical visualizer.
+
+[](https://ohmjs.org/editor)
+
+You can [try the visualizer online](https://ohmjs.org/editor).
+
+To see the text trace for a grammar `g`, just use the [`g.trace()`](api-reference.md#Grammar.trace)
+method instead of `g.match`. It takes the same arguments, but instead of returning a MatchResult
+object, it returns a Trace object — calling its `toString` method returns a string describing
+all of the decisions the parser made when trying to match the input. For example, here is the
+result of `g.trace('ab').toString()` for the grammar `G { start = letter+ }`:
+
+
+
+```
+ab ✓ start ⇒ "ab"
+ab ✓ letter+ ⇒ "ab"
+ab ✓ letter ⇒ "a"
+ab ✓ lower ⇒ "a"
+ab ✓ Unicode [Ll] character ⇒ "a"
+b ✓ letter ⇒ "b"
+b ✓ lower ⇒ "b"
+b ✓ Unicode [Ll] character ⇒ "b"
+ ✗ letter
+ ✗ lower
+ ✗ Unicode [Ll] character
+ ✗ upper
+ ✗ Unicode [Lu] character
+ ✗ unicodeLtmo
+ ✗ Unicode [Ltmo] character
+ ✓ end ⇒ ""
+```
+
+## Quick reference
+
+
diff --git a/doc/patterns-and-pitfalls.md b/doc/patterns-and-pitfalls.md
index 61af948f..313dbd62 100644
--- a/doc/patterns-and-pitfalls.md
+++ b/doc/patterns-and-pitfalls.md
@@ -119,4 +119,4 @@ This evaluates to either (a) `undefined`, if the node has no child, or (b) the r
### Handling the built-in list rules
-When using the built-in list rules (`listOf`, etc.) in your grammar, you usually don't need to write semantic actions for them. Instead, you can use the [built-in `asIteration` operation](./api-reference.md#asIteration).
+When using the built-in list rules (`listOf`, etc.) in your grammar, you usually don't need to write semantic actions for them. Instead, you can use the [built-in `asIteration` operation](./api-reference.md#asiteration).
diff --git a/doc/quick-reference.md b/doc/quick-reference.md
deleted file mode 100644
index 409172b9..00000000
--- a/doc/quick-reference.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# Quick reference
-
-
diff --git a/doc/syntax-reference.md b/doc/syntax-reference.md
index 70ef71af..18fdcdbf 100644
--- a/doc/syntax-reference.md
+++ b/doc/syntax-reference.md
@@ -2,7 +2,7 @@
This document describes the syntax of the _Ohm language_, which is a variant of parsing expression grammars (PEGs). If you have experience with PEGs, the Ohm syntax will mostly look familiar, but there are a few important differences to note:
-- When naming rules, **case matters**: whitespace is implicitly skipped inside a rule application if the rule name begins with an uppercase letter. For further information, see [Syntactic vs. Lexical Rules](#syntactic-lexical).
+- When naming rules, **case matters**: whitespace is implicitly skipped inside a rule application if the rule name begins with an uppercase letter. For further information, see [Syntactic vs. Lexical Rules](#syntactic-vs-lexical-rules).
- Grammars are purely about recognition: they do not contain semantic actions (those are defined separately) or bindings. The separation of semantic actions is one of the defining features of Ohm — we believe that it improves modularity and makes both grammars and semantics easier to understand.
- Alternation expressions support _case names_, which are used in [inline rule declarations](#inline-rule-declarations). This makes semantic actions for alternation expressions simpler and less error-prone.
- Ohm does not (yet) support semantic predicates.
@@ -44,7 +44,7 @@ Matches exactly the characters contained inside the quotation marks.
Special characters (`"`, `\`, and `'`) can be escaped with a backslash — e.g., `"\""` will match a literal quote character in the input stream. Other valid escape sequences include: `\b` (backspace), `\f` (form feed), `\n` (line feed), `\r` (carriage return), and `\t` (tab), as well as `\x` followed by 2 hex digits and `\u` followed by 4 hex digits, for matching characters by code point.
-The \u{hexDigits} escape sequence can be used to represent _any_ Unicode code point, including code points above `0xFFFF`. E.g., `"\u{1F639}"` will match `'😹'`. (_New in Ohm v16.3.0._)
+The \u{hexDigits} escape sequence can be used to represent _any_ Unicode code point, including code points above `0xFFFF`. E.g., `"\u{1F639}"` will match `'😹'`. (_New in Ohm v16.3.0._)
**NOTE:** For grammars defined in a JavaScript string literal (i.e., not in a separate .ohm file), it's recommended to use a [template literal with the String.raw tag](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/raw). Without `String.raw`, you'll need to use double-escaping — e.g., `\\n` rather than `\n`.
@@ -75,13 +75,13 @@ Matches the body of the _parameterized rule_ named _ruleName_, substituting the
Matches the expression _expr_ repeated 0 or more times. E.g., `"a"*` will match `''`, `'a'`, `'aa'`, ...
-Inside a _syntactic rule_ — any rule whose name begins with an upper-case letter — spaces before a match are automatically skipped. E.g., `"a"*` will match `" a a"` as well as `"aa"`. See the documentation on [syntactic and lexical rules](#syntactic-lexical) for more information.
+Inside a _syntactic rule_ — any rule whose name begins with an upper-case letter — spaces before a match are automatically skipped. E.g., `"a"*` will match `" a a"` as well as `"aa"`. See the documentation on [syntactic and lexical rules](#syntactic-vs-lexical-rules) for more information.
expr +
Matches the expression _expr_ repeated 1 or more times. E.g., `letter+` will match `'x'`, `'xA'`, ...
-As with the `*` operator, spaces are skipped when used in a [syntactic rule](#syntactic-lexical).
+As with the `*` operator, spaces are skipped when used in a [syntactic rule](#syntactic-vs-lexical-rules).
expr ?
@@ -93,7 +93,7 @@ Tries to match the expression _expr_, succeeding whether it matches or not. No i
Matches the expression `expr1` followed by `expr2`. E.g., `"grade" letter` will match `'gradeA'`, `'gradeB'`, ...
-As with the `*` and `+` operators, spaces are skipped when used in a [syntactic rule](#syntactic-lexical). E.g., `"grade" letter` will match `' grade A'` as well as `'gradeA'`.
+As with the `*` and `+` operators, spaces are skipped when used in a [syntactic rule](#syntactic-vs-lexical-rules). E.g., `"grade" letter` will match `' grade A'` as well as `'gradeA'`.
### Alternation
@@ -117,7 +117,7 @@ Succeeds if the expression `expr` cannot be matched, and does not consume anythi
# expr
-Matches _expr_ as if in a lexical context. This can be used to prevent whitespace skipping before an expression that appears in the body of a syntactic rule. For further information, see [Syntactic vs. Lexical Rules](#syntactic-lexical).
+Matches _expr_ as if in a lexical context. This can be used to prevent whitespace skipping before an expression that appears in the body of a syntactic rule. For further information, see [Syntactic vs. Lexical Rules](#syntactic-vs-lexical-rules).
### Comment
@@ -166,13 +166,13 @@ as well as multiline (`/* */`) comments like:
`end`: Matches the end of the input stream. Equivalent to `~any`.
-caseInsensitive<terminal>: Matches _terminal_, but ignoring any differences in casing (based on the simple, single-character Unicode case mappings). E.g., `caseInsensitive<"ohm">` will match `'Ohm'`, `'OHM'`, etc.
+caseInsensitive<terminal>: Matches _terminal_, but ignoring any differences in casing (based on the simple, single-character Unicode case mappings). E.g., caseInsensitive<"ohm"> will match `'Ohm'`, `'OHM'`, etc.
-ListOf<elem, sep>: Matches the expression _elem_ zero or more times, separated by something that matches the expression _sep_. E.g., `ListOf` will match `''`, `'a'`, and `'a, b, c'`.
+ListOf<elem, sep>: Matches the expression _elem_ zero or more times, separated by something that matches the expression _sep_. E.g., ListOf<letter, ",">, will match `''`, `'a'`, and `'a, b, c'`.
NonemptyListOf<elem, sep>: Like `ListOf`, but matches _elem_ at least one time.
-listOf<elem, sep>: Similar to `ListOf` but interpreted as [lexical rule](#syntactic-lexical).
+listOf<elem, sep>: Similar to ListOf<elem, sep> but interpreted as [lexical rule](#syntactic-vs-lexical-rules).
applySyntactic<ruleName>: Allows the syntactic rule _ruleName_ to be applied in a lexical context, which is otherwise not allowed. Spaces are skipped _before_ and _after_ the rule application. _New in Ohm v16.1.0._
@@ -182,14 +182,14 @@ as well as multiline (`/* */`) comments like:
### Grammar Inheritance
-grammarName <: supergrammarName { ... }
+grammarName <: supergrammarName { ... }
Declares a grammar named `grammarName` which inherits from `supergrammarName`.
### Defining, Extending, and Overriding Rules
In the three forms below, the rule body may optionally begin with a `|` character, which will be
-ignored. Also note that in rule names, [**case is significant**](#syntactic-lexical).
+ignored. Also note that in rule names, [**case is significant**](#syntactic-vs-lexical-rules).
ruleName = expr
@@ -252,7 +252,7 @@ AddExp = AddExp_plus
AddExp_plus = AddExp "+" MulExp
```
-Syntactic vs. Lexical Rules
+### Syntactic vs. Lexical Rules
diff --git a/doc/typescript.md b/doc/typescript.md
index 7fc66936..b0a710c7 100644
--- a/doc/typescript.md
+++ b/doc/typescript.md
@@ -17,13 +17,13 @@ To enable grammar-specific type definitions:
2. Put your grammar in a separate .ohm file, if it isn't already.
3. Use the Ohm CLI to generate a bundle (.ohm-bundle.js) for your grammar, along with the associated type definitions (.d.ts). For example, if your grammar is in `src/my-grammar.ohm`:
- ```
+ ```bash
npx ohm generateBundles --withTypes 'src/*.ohm'
```
...will create `src/my-grammar.ohm-bundle.js` and `src/my-grammar.ohm-bundle.d.ts`. You can directly import the bundle like this:
- ```
+ ```js
import grammar from './my-grammar.ohm-bundle'
```
diff --git a/doc/used-by.md b/doc/used-by.md
deleted file mode 100644
index de32cb11..00000000
--- a/doc/used-by.md
+++ /dev/null
@@ -1,12 +0,0 @@
-# Used by…
-
-Ohm has been around for over 10 years, and is used in a wide variety of interesting projects. Here are some of our favourites:
-
-- The [The ERC-funded OnePub project](https://cordis.europa.eu/project/id/101113339) is using Ohm in a collaborative, local-first editor for [Asciidoc](https://asciidoc.org/) documents.
-- [Ambsheets, a spreadsheet for exploring scenarios](https://www.inkandswitch.com/ambsheets/notebook/) by Ink & Switch.
-- [SchuBu](https://de.schubu.org/p768/programmieren), a free-to-use digital schoolbook in use by over 100.000 students in Austria, uses Ohm for the Gambu-Script language.
-- [Bruno](https://usebruno.com/) is an open source IDE for exploring and testing APIs. They used Ohm to develop [the Bru markup language](https://docs.usebruno.com/bru-lang/overview).
-- [WELLE](https://www.nime.org/proceedings/2020/nime2020_paper114.pdf) by Jens Vetter from Kunstuniversität Linz, is a web-based music environment for the blind.
-- [Wildcard](https://www.geoffreylitt.com/wildcard/), by Geoffrey Litt from MIT, is a browser extension that empowers anyone to modify websites to meet their own specific needs. It uses Ohm for its spreadsheet language.
-- [turtle.audio](http://turtle.audio) is an audio environment where simple text commands generate lines that can play music.
-- [Shadama](https://tinlizzie.org/~ohshima/shadama2/live2017/), by Yoshiki Ohshima et al, is a live programming environment for particle simulation.